





















Qu’est-ce que la RAD et la LAD ?
La Reconnaissance Automatique de Documents (RAD) et la Lecture Automatique de Documents (LAD) sont deux technologies étroitement liées qui simplifient et automatisent la gestion des documents d’entreprise. Elles travaillent de concert pour transformer les documents non structurés en données exploitables.
Le rôle de la RAD est d’identifier et de classer automatiquement les différents types de documents. Par exemple, sans intervention humaine, elle peut reconnaître qu’un document est une facture, un bon de commande ou un bulletin de paie. Pour y parvenir, les systèmes de RAD utilisent l’apprentissage automatique (machine learning) et des techniques d’analyse de la mise en page. Ils analysent la structure du document, la présence de mots-clés spécifiques (« facture », « bon de commande ») et les logos pour déterminer sa nature.
La LAD est la technologie qui extrait des informations spécifiques à partir des documents une fois qu’ils ont été classés par la RAD. Si la RAD a identifié un document comme étant une facture, la LAD va lire et collecter des données précises comme le numéro de facture, le montant total ou la date d’échéance. Pour cela, la LAD utilise des technologies de Reconnaissance Optique de Caractères (OCR) pour convertir le texte d’une image en texte éditable. Le système recherche ensuite les informations en se basant sur la structure du document et les règles définies par la RAD. Par exemple, il est paramétré pour chercher le numéro de facture près du terme « N° Facture » ou le montant total à proximité du « Total TTC ».
| Découvrez-en plus sur la capture de données |
Fonctionnement des technologies RAD et LAD
1. La Reconnaissance Automatique de Documents (RAD)
Le fonctionnement de la RAD repose sur une série d’étapes d’analyse :
L’analyse de la mise en page (Layout Analysis) :
Cette première phase est cruciale pour « comprendre » la structure visuelle du document. Le logiciel va découper le document en plusieurs zones pour identifier :
- Le type de mise en page : est-ce une facture, un tableau, un formulaire ?
- Les blocs de texte : titres, en-têtes, paragraphes.
- Les éléments graphiques : logos, images, lignes, cases à cocher.
- L’orientation du document.
Cette analyse permet d’obtenir une « carte d’identité » visuelle du document.
L’analyse du contenu sémantique (Semantic Analysis) :
Après l’analyse de la mise en page, le système RAD se concentre sur le contenu textuel. Il va utiliser des technologies d’OCR (Reconnaissance Optique de Caractères) pour convertir l’image du document en texte lisible par la machine. Une fois le texte numérisé, il va chercher des mots-clés et des expressions spécifiques qui sont des indicateurs forts de la nature du document.
Exemples :
- Facture : « Facture n° », « Montant Total », « TVA », « Date d’échéance ».
- Bon de commande : « Commande n° », « Date de livraison », « Prix unitaire ».
- Contrat : « Contrat de travail », « Conditions générales », « Employé », « Employeur ».
Le traitement par des modèles (Pattern Matching) :
C’est le cœur de la RAD. Les données récoltées lors des étapes précédentes (mise en page et contenu textuel) sont comparées à une base de modèles prédéfinis. Chaque modèle correspond à un type de document connu.
Le système de RAD utilise des algorithmes d’apprentissage automatique (machine learning) pour associer le document à l’un de ces modèles. Plus il y a de documents traités, plus l’algorithme « apprend » et devient précis. Il va par exemple reconnaître un logo ou une mise en page spécifique même si le format exact du document varie légèrement.
Le score de confiance et la classification :
À l’issue de l’analyse, le système attribue un score de confiance pour chaque classification possible. Si un document ressemble à une facture à 98 % et à un bon de commande à 2 %, il sera classé comme une facture. Si le score de confiance est trop faible (par exemple 40 %), le document est mis de côté pour une vérification manuelle, garantissant la fiabilité du processus.
Le résultat : la classification :
Le résultat final de la RAD est la catégorisation du document. Le document est étiqueté avec son type (ex: « Facture Client »), ce qui permet au système de LAD de savoir exactement quel modèle d’extraction appliquer pour en extraire les informations clés. Sans cette classification initiale, la LAD serait incapable de fonctionner correctement.
2. La Lecture Automatique de Documents (LAD)
Le fonctionnement de la RAD repose sur une série d’étapes d’analyse :
Numérisation et Reconnaissance Optique de Caractères (OCR) :
Avant toute chose, le document, qu’il soit physique ou numérique, doit être rendu lisible par la machine. C’est le rôle de l’OCR. L’OCR convertit l’image du document (JPEG, PDF scanné) en un fichier texte. L’efficacité du LAD dépend en grande partie de la qualité de cette étape. Une mauvaise numérisation ou une écriture manuscrite illisible peut réduire la précision.
Localisation des Champs (Field Localization) :
Une fois le texte numérisé, le moteur de LAD, en se basant sur le type de document identifié par la RAD, sait quels champs il doit extraire. Il va alors localiser ces champs sur le document. Par exemple, pour une facture, il sait qu’il doit trouver le numéro de facture, le montant total, et les coordonnées de l’expéditeur.
Il utilise plusieurs techniques pour cela :
- Analyse de la mise en page : Le logiciel analyse la position des champs. Par exemple, le numéro de facture se trouve souvent en haut à droite.
- Recherche de mots-clés : Le logiciel cherche des étiquettes (labels) qui précèdent ou suivent les données, comme « N° Facture: », « Total TTC: », « Date: ».
- Reconnaissance de motifs : La LAD est capable de reconnaître des motifs spécifiques, comme les numéros de téléphone, les adresses email (grâce à l’arobase @), ou les numéros de siret (grâce à leur format de 14 chiffres).
Extraction et Structuration des Données :
Une fois les champs localisés, la LAD extrait les données correspondantes. Par exemple, si le système a trouvé le label « Total TTC: » suivi de « 125,50 € », il extrait la valeur « 125,50 ». Il transforme cette information brute en une donnée structurée, par exemple un champ nommé « MontantTotal » avec la valeur « 125.50 ».
Post-Traitement et Validation :
Pour garantir la fiabilité des données, la LAD effectue des vérifications automatiques.
- Vérification de la validité : Le système peut s’assurer que les dates sont dans un format correct, que les montants sont bien des nombres, etc.
- Vérification croisée : Pour une facture, le système peut calculer la somme des lignes de produits pour vérifier que le total correspond bien au montant extrait.
- Vérification externe : Les données extraites peuvent être comparées à une base de données existante. Par exemple, le nom du fournisseur extrait est confronté à une liste de fournisseurs déjà connus.
Exportation et Intégration :
La dernière étape consiste à exporter les données structurées vers le système de l’entreprise (ERP, logiciel de comptabilité, CRM, etc.). La LAD peut générer des fichiers au format XML, JSON ou CSV, qui sont ensuite intégrés de manière transparente, sans aucune saisie manuelle.
3. Le processus combiné RAD/LAD
Le processus combiné de la RAD et de la LAD est une chaîne de traitement automatisée qui transforme un simple document en une information structurée et exploitable.
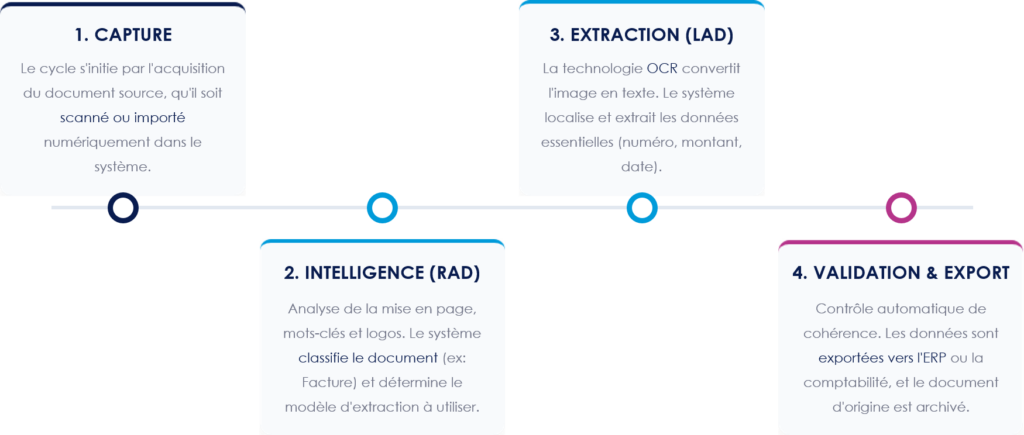
Résultat : Un flux de données sécurisé, actionnable en quelques secondes, avec une traçabilité totale.
Cas d’utilisation concrets fictif dans les entreprises
1.Traitement des factures fournisseurs
Chez « Altius », une entreprise de distribution de matériel de sport, l’équipe comptable reçoit des centaines de factures fournisseurs par jour, la plupart par e-mail ou par courrier. Le processus est manuel : un employé ouvre l’e-mail, télécharge la facture, la saisit manuellement dans le logiciel de comptabilité, et la classe dans un dossier. Ce processus est lent, coûteux et source d’erreurs de saisie.
Solution LAD/RAD :
Réception et Identification (RAD)
- Centralisation : Toutes les factures arrivent sur une adresse e-mail dédiée pilotée par la solution.
- Tri automatique : Le système de Reconnaissance Automatique de Documents (RAD) distingue les « Factures Fournisseurs » des autres documents (publicités, bons de commande) via l’analyse de mots-clés ($Total$ $TTC$, Facture, etc.).
Extraction des Données (LAD)
- Lecture optique (OCR) : Extraction automatique des informations critiques (nom du fournisseur, numéro de facture, date d’échéance).
- Structuration : Transformation des données brutes en informations exploitables pour le système comptable.
- Calcul des taxes : Récupération précise des montants HT, TVA et TTC.
Les données extraites sont automatiquement intégrées dans le logiciel comptable de « Altius ». Le système vérifie la cohérence des montants et rapproche la facture du bon de commande initial. Si toutes les informations sont correctes, la facture est validée et prête pour le paiement. En cas de non-concordance, la facture est signalée pour une vérification humaine rapide.
Le temps de traitement d’une facture est passé de plusieurs minutes à quelques secondes. Les erreurs de saisie sont éliminées, la gestion de la trésorerie est améliorée, et l’équipe comptable peut se concentrer sur l’analyse financière plutôt que sur la saisie de données.
2. Gestion des dossiers clients et des contrats
Chez « ImmoPro », une agence immobilière, les agents créent des dossiers clients pour chaque nouveau locataire. Ces dossiers contiennent des documents variés : pièces d’identité, justificatifs de domicile, contrats de location signés. Chaque document doit être vérifié, renommé, puis classé manuellement dans le dossier numérique du client. Ce processus est long et fastidieux.
Solution LAD/RAD :
Collecte et Classification (RAD)
- Portail Sécurisé : Centralisation du dépôt des documents par le client sur la plateforme ImmoPro.
- Tri Intelligent : Identification automatique de la nature des pièces (Pièce d’identité, Contrat de location, Justificatif de domicile).
Extraction Ciblée (LAD)
- Données Identité : Lecture automatique des noms, prénoms, dates de naissance et adresses.
- Données Contractuelles : Extraction des dates clés (début et fin de bail) et du montant du loyer mensuel.
Les données extraites sont utilisées pour créer un nouveau dossier client dans le système de gestion d’ImmoPro. Le dossier est automatiquement renommé avec le nom du client, et chaque document est classé dans le bon sous-dossier, avec les métadonnées extraites.
Les dossiers clients sont créés en quelques minutes et sans erreur. Les agents immobiliers sont plus réactifs et peuvent se concentrer sur le suivi des clients et la conclusion de contrats, améliorant la satisfaction client et la productivité de l’agence.
Intégration des solutions RAD et LAD
| Avantages | Bénéfices Clés | Impact Opérationnel |
| Efficacité & Gain de temps |
Anticiper l’ensemble des dépenses, au-delà de l’achat initial. | – Intégration (API, connecteurs CRM/ERP). – Formation des utilisateurs. – Maintenance et support technique |
| Rentabilité & Précisions | Transformer des intentions floues en indicateurs chiffrés (KPI). | – Réduire de 40% le temps de traitement des factures. – Atteindre 100% de conformité RGPD via la centralisation |
| Sécurité & Conformité |
Assurer l’évolutivité et l’intégration à l’écosystème numérique. | – Compatibilité avec le télétravail. – Capacité à absorber la croissance (nouveaux bureaux, volume de données) |
Avantages pour la gestion documentaire

L’avenir de la RAD/LAD
En conclusion, la RAD / LAD est le moteur d’une véritable transformation de la gestion documentaire. En automatisant l’ensemble du cycle, de la classification à l’intégration des données, ces technologies libèrent les entreprises des contraintes des processus manuels.
Par ailleurs, l’avenir de la RAD/LAD s’annonce comme une transformation radicale de la gestion documentaire, avec l’intelligence artificielle au cœur de son évolution. L’intégration croissante de l’IA et du deep learning permettra aux solutions de devenir plus performantes, capables de s’adapter à des documents variés et complexes sans nécessiter de paramétrage manuel.
Cette évolution vers une reconnaissance sémantique permettra de comprendre le sens des informations bien au-delà de la simple extraction de champs. Ces technologies seront également des piliers de l’hyper-automatisation, combinées avec la RPA et le BPM pour créer des chaînes de traitement entièrement autonomes, gérant ainsi des volumes massifs de documents avec une intervention humaine minimale. Enfin, la gestion documentaire deviendra proactive et intelligente.
Les systèmes de demain ne se contenteront plus d’extraire des données, mais les analyseront pour détecter des anomalies, suggérer des actions, voire même anticiper des besoins, transformant ainsi la GED en un véritable centre névralgique capable de fournir des informations précieuses pour la prise de décision stratégique.
| Besoin de conseils ? Contactez-nous |
Commentaires récents